
.
Twext syncs texts, timings, vocals, contexts and more.
Error and trial failed to connect twext. It was too hard to edit. You wanted to just edit.
Now you edit twext easy. In many versions. All aligned in textarea. Any variable width or monospace font. Any language you like.
TWEXTAREA 1ab SEGMENT SYNC 2ab 3. TAP VOCAL TEXT N=N SEGMENT ALIGNMENT 4abcd CORRESPONDENCE 4efghijkl N=N IPA ALIGNMENTS 4mnop ABC ALIGN BITEXT CHUNKS 5a-z TIME ALIGNED BITEXT TAG QUESTION STRUCTURE 7a-7p PICTURE SORT IN TIERED CAROUSELS 8a-8k TOGGLE TWEXT FORMS/VERSIONS 9a-9z TOO MUCH TWEXT 10a-10c FORMAT TWEXT 11a-11h FACE MIX 12a-12q
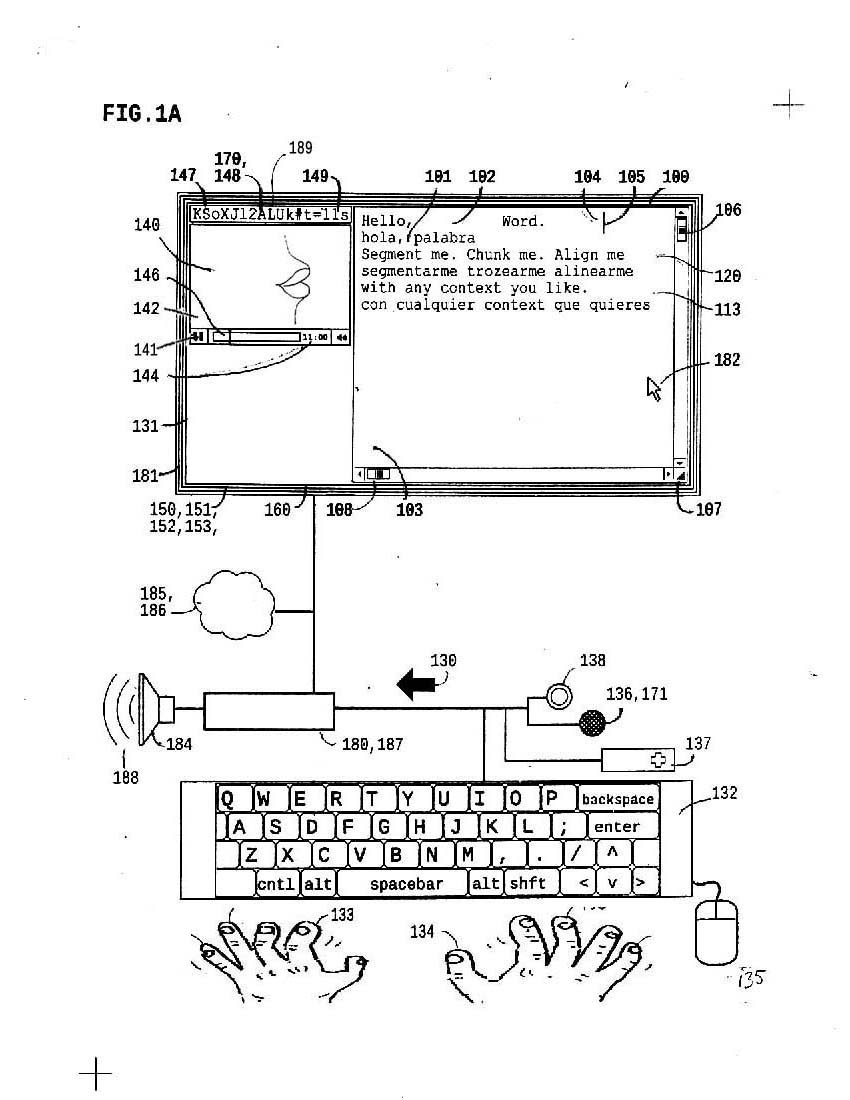
1a represents a modern computing environment, with camera/mic, media player and textarea; for this invention, a full tactile keyboard is ideal, but haptic feedback will improve the mobile experience.

|
1) fact: is there prior art? 2) opinion: are these inventive steps? |
1b represents twext control in textarea. HTML5 span measure makes the first known way to effectively align editable twext in textarea.
WYSIWYG we got.
Any font, any language. Proportional, monospace, Asian, Latin; edit twext live in textarea.
With your sound in where? your glottus.


2a shows syllables controlled within text in textarea; where 1b shows translations twext, now timings are aligned. Timing values are defined in TAP process.
2b shows syllabified text aligned with timings in textarea, next to a media player [like youtube], which is above some pictures arranged in "tiered carousels"; this picture sorter makes it easy to associate pictures with specific text and associated vocalizations.
First we want perfect timings synchronizing each text syllable with corresponding syllable of vocalization. as described below, there are multiple novel controls which presents a UI challenge; voice control will be nice.

3a represents a "Human-Computation" feedback loop, where software guesses timings of a given audio segment, then human corrections improve the timings (and teach the software)
the slash over the textarea represents a fast switch from normal textarea content to twextarea; we have this working in prototype.

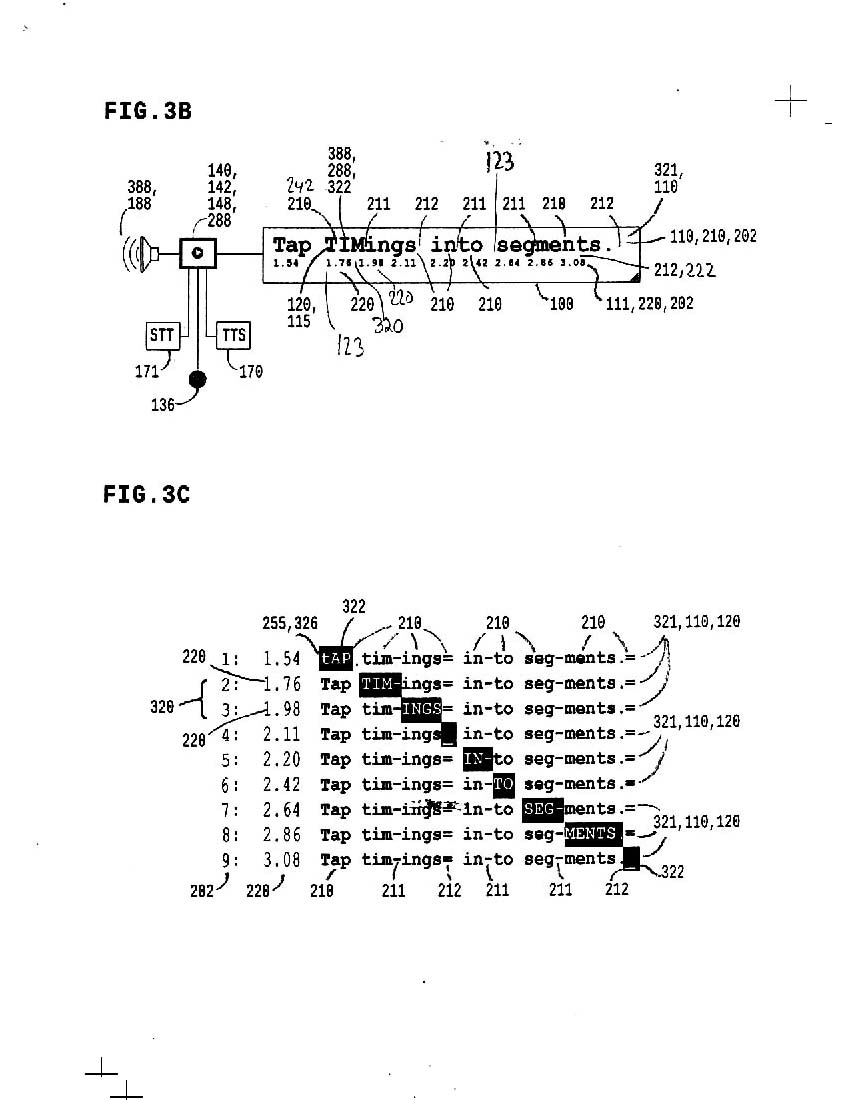
3b shows a nifty trick: see the word "TIMings"? We can CAPitalize syllables in plaintext precisely while vocalization is reproduced.
I call it "Vocal Text".
"Vocalization" means voice saying words in text: optionally recorded like youtube, generated like Text-To-Speech, or even Speech-To-Text with real-time human vocals; SST sync will be challenging, but for now you can TAP while saying a text and produce Vocal Text live.
3c represents "CAPcase" or uppercase element moving through plaintext, precisely timed with start timings and end timings for each syllable or segment; the equals "=" sign is used as a pause marker.

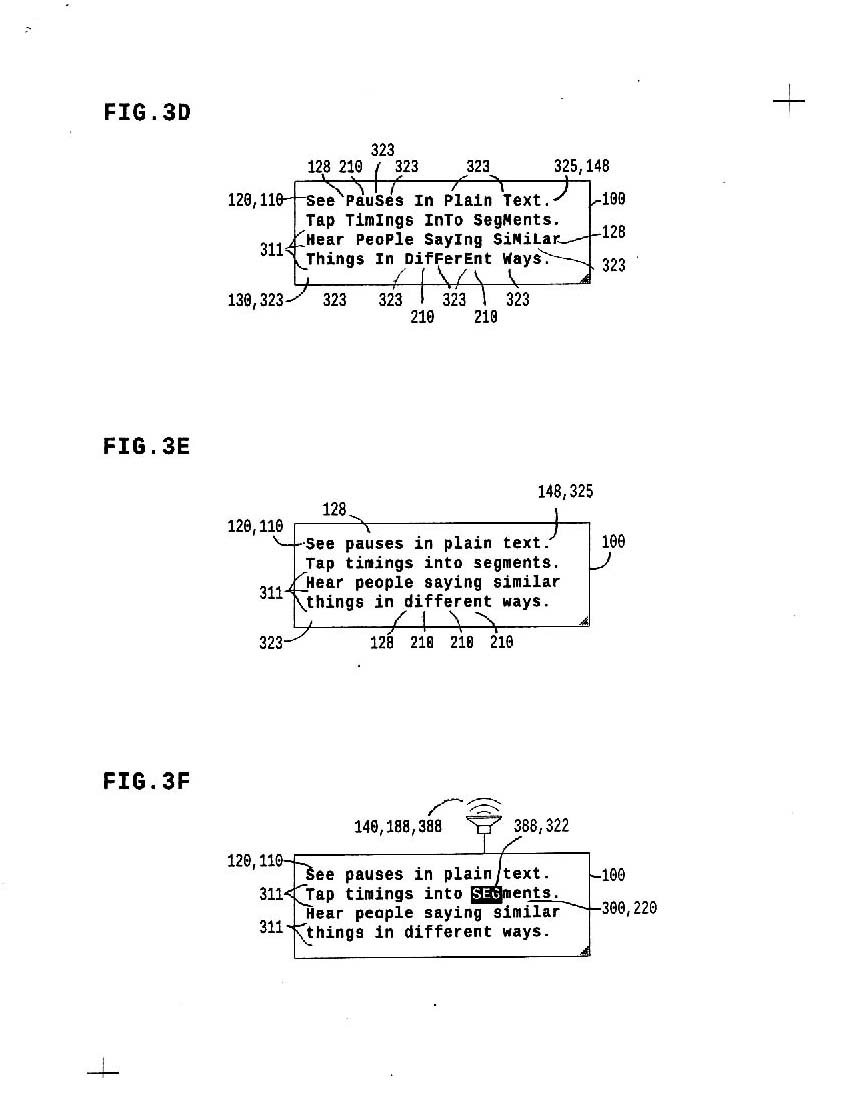
3d-f show a simple control to see syllables in text, so you can see what you'll tap before you tap.
As you see in the gif below, there are a bunch of ways to do this.

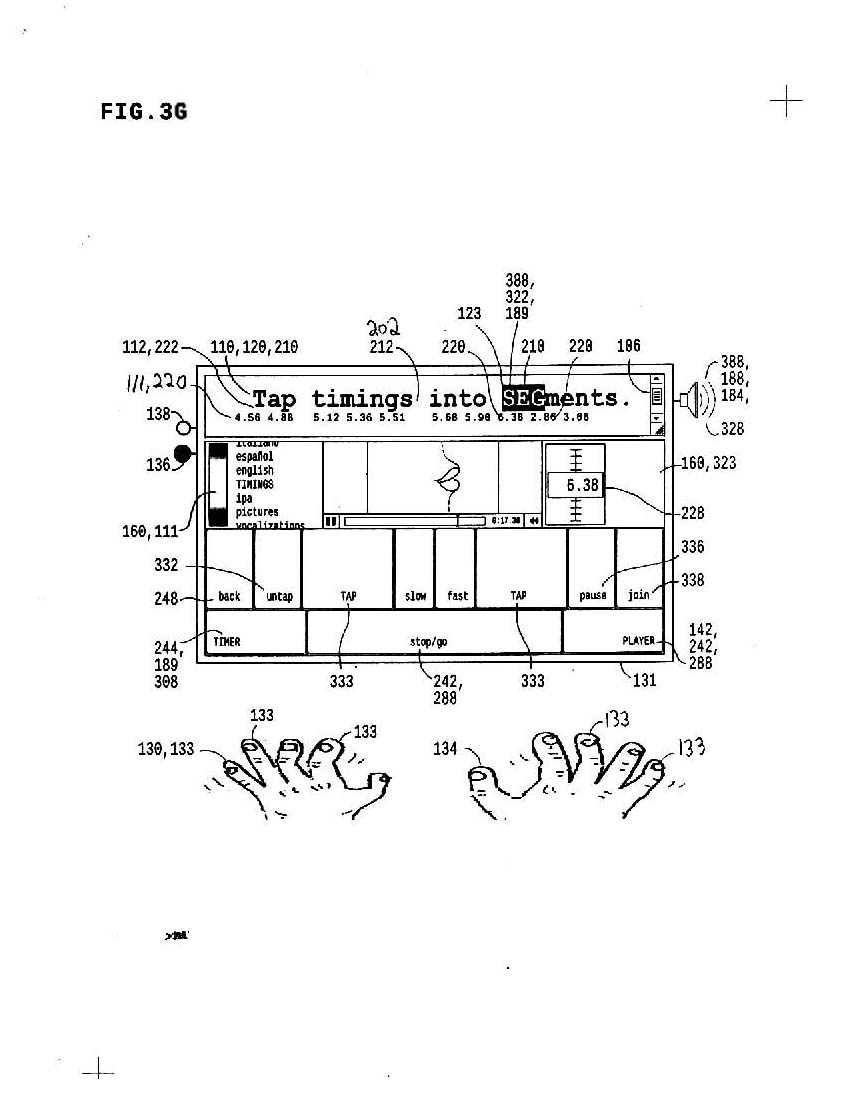
3g represents the system on a mobile tablet, with touch input areas defined; there are literally zillions of ways to configure this, but the basic idea is:
a) you TAP with multiple fingers
b) your taps drive CAPcase through the text
c) if you tap accurately, you SYNC vocals with text
d) separate keys or input areas add timing controls
* PAUSE, end CAPcase in this syllable but don't start next syllable
* JOIN, delete next pause or join this and next syllable into one segment
* UNTAP if you tap too soon, untap
* BACK, go back and retap this line more accurately
* STOP/GO
all these controls are working in prototype; we even have a GAME working where you play against existing perfect timings

3hij describe JOIN and PAUSE controls: from 3h to 3i, the "=" pause marker and corresponding timing are deleted; from 3i to 3j, a new pause marker is added; these controls are built and tested and work great.
pauses in speech can ring with meaning; we control pauses with extreme precision while TAP timing CAPcase in plaintext.


3klm represents a way to control Vocal Text position over image or video, so we see text as close as possible to lips.

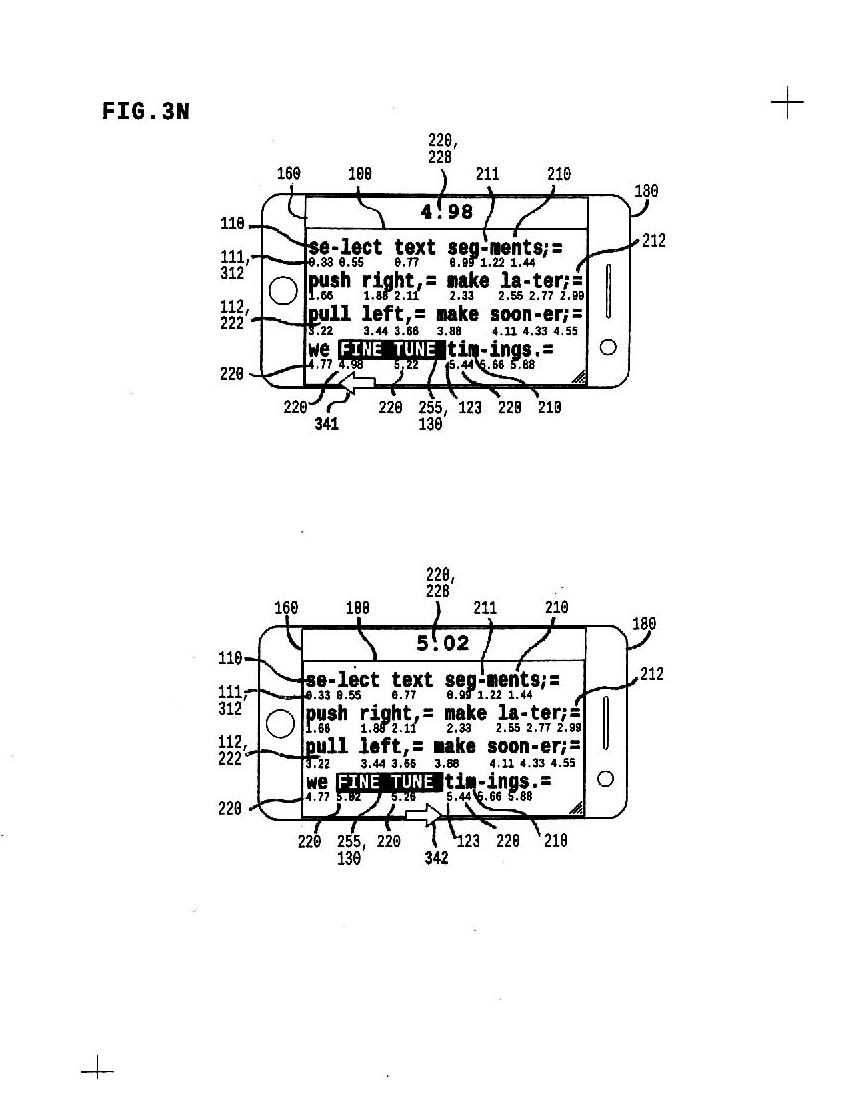
3n represents a way to
a) select some text
b) adjust timings of selected text
c) so you can "fine tune" timings
Perfect timings is what we want.


3o Average Timings is probably a great way to get perfect timings; multiple re-timings from a single person can work; we really want to test average timings from multiple peoples, so c) we find out if b) we get perfect timings and a) we have more fun
make game teach tap sync skills
3p shows a GAME with live feedback; given PERFECT TIMINGS, you play this game to learn how to sync perfect timings in real-time; it's fun.
Try it.

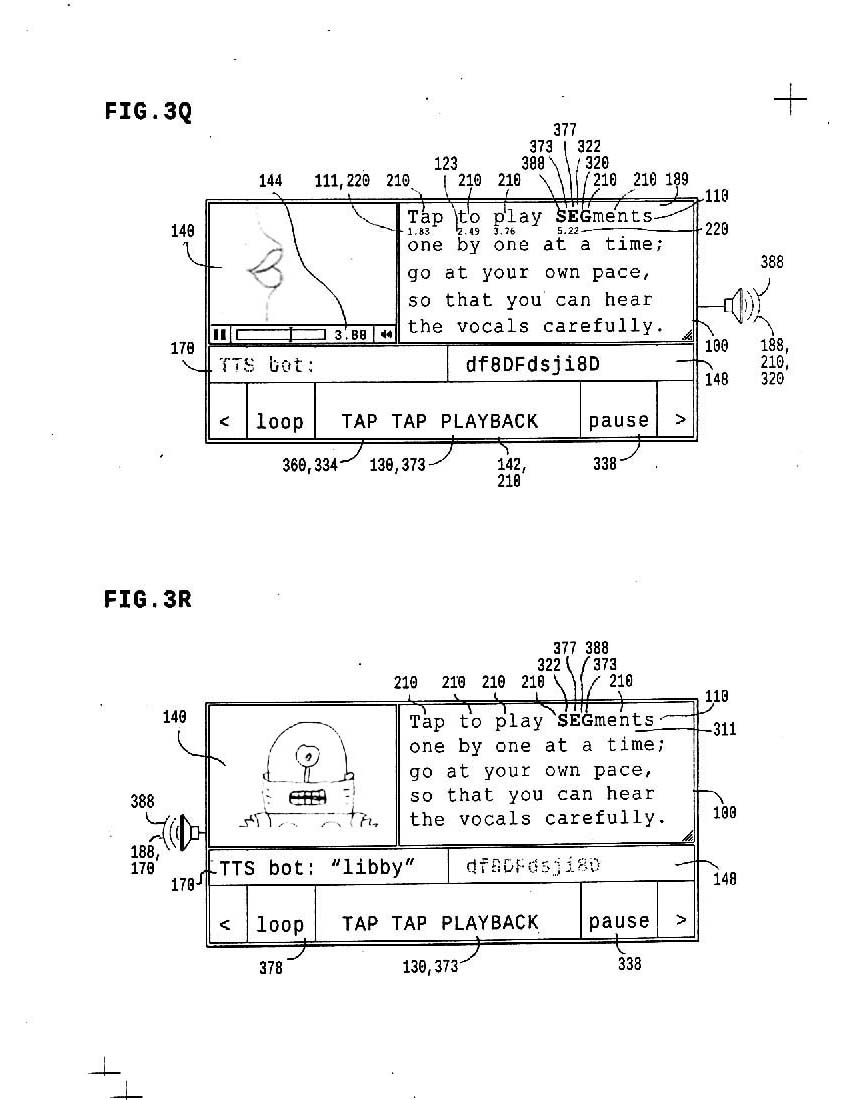
3q represents TAPS controlling segment *playback*, where each tap *plays* a perfectly timed audio segment; so if you tap along precisely, then you construct accurately timed playback; so you get real-time audio feedback while playing the game, or tap more slowly to clearly hear new sounds in vocalization.
tap TTS
3q represents TAPS control of TTS production, playback speed, pause insertion and so on, so you hear text to speech at speeds you want, or control a specific text to speech performance.

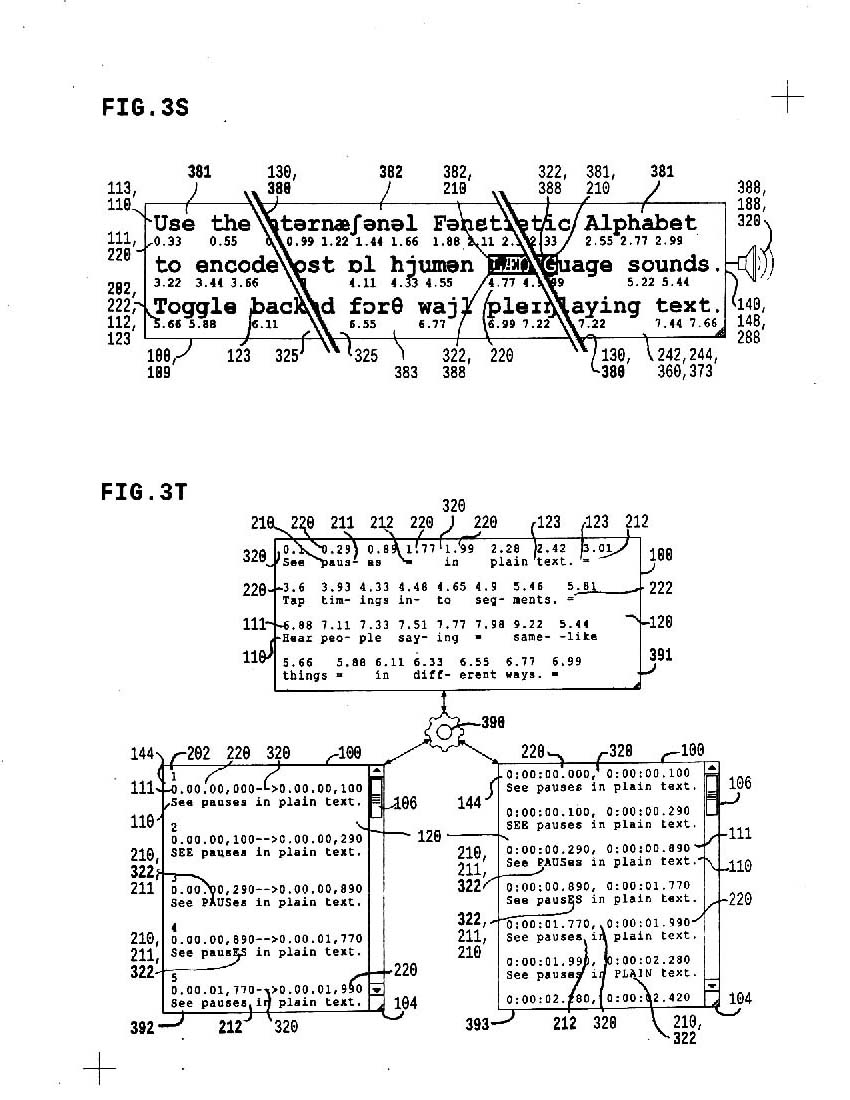
3s shows an "IPA switch" from native writing system to the same vocalization encoded in the International Phonetic Alphabet; it'll be easy to switch back and forth, even while tapping or playing
vocal text syllabic sync in any caption format
3t shows conversion from the twext format to standard caption formats like SUB, SRT etc; it means you can sync syllables and make playback in CLOSED CAPTIONS like you see on TV, or even captions in youtube, check it out.
chrome buggy, most other browsers work fine

3u shows arabic keyboard version and user customizable keyboard; i like touch-type fast keyboard layout, but you might like mapping "t" to "tap" and "b" to back; ok, customize keyboard? nothing new here, no claim other than part of system using all thumbs and fingers on keyboard to sync text faster/better and funner than before.
same timings, variably expressed
we tried averaging errors in each timing, that fails to score properly; now we control timings more ways, especially to find/use timing patterns..
timing patterns
so if 10 taps are each 1 second too soon, score is 1s off total (.1/seg each, not 10s total), so we score better; timing pattern control will prolly allow game to start anywhere in loop, so you just tap starting anywhere, play and score
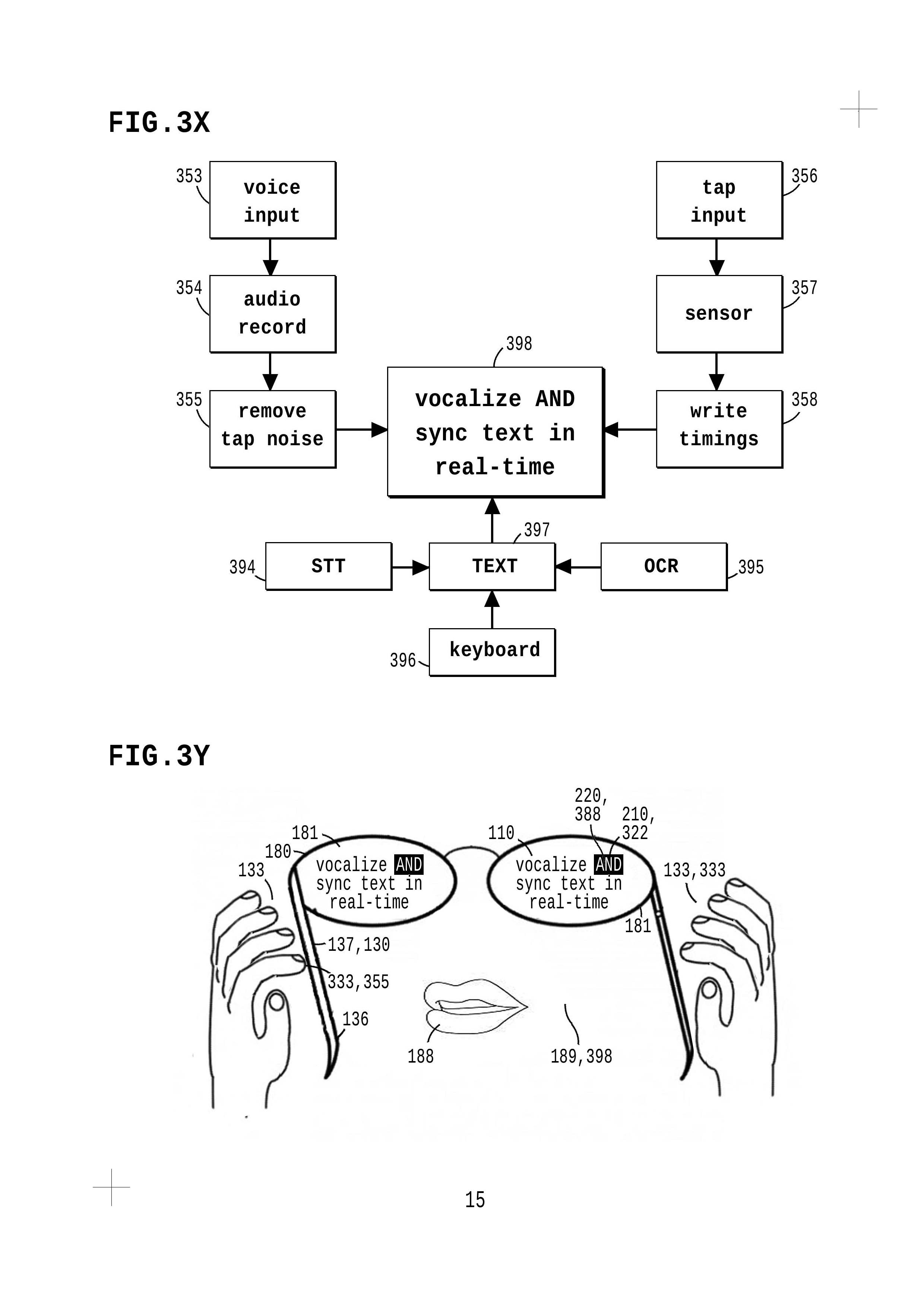
3x flow shows way to tap, talk and sync text in realtime; easy way to sync your voice w/ any textarea text, then compare vocal expressions.
touch sound you see in text
3y sees glass tap live vocal text; this'll prolly look quaint in 2030 haha whatever; it's fun to tap sync your voice with any text, did you try it?

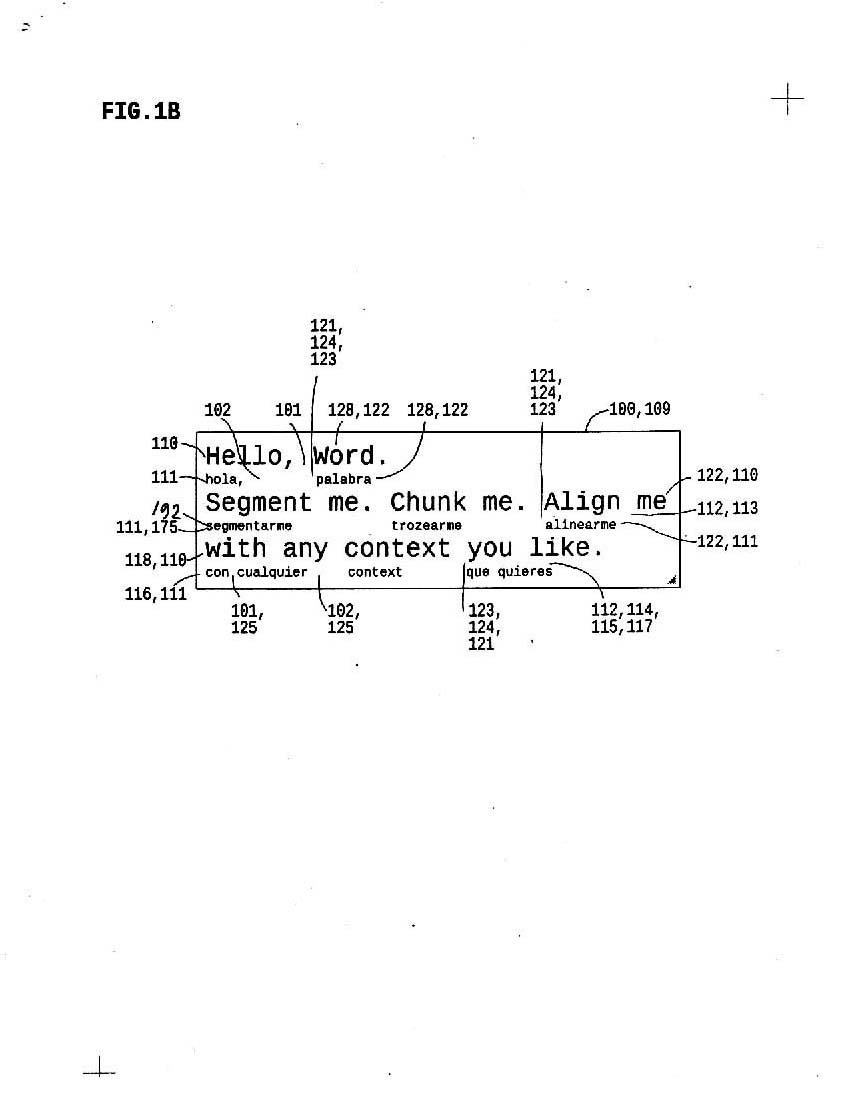
4a shows unformatted plaintext on two lines; for every segment (syllable or pause) there is a timing.
4b shows twext format plaintext: small-sized context such as timings shown and large-sized text; each timings aligns with each segment
4c compresses 4b the contents; context is aligned by the word.
4d hides the pause and syllable markers; context is aligned by the line.
Where we always control one timing context segment for each text segment, we can control multiple views of the data in twextarea.

edit like plain-text

If we edit text, corresponding timings are added or deleted.
So we can edit the transcription of a vocalization without screwing up timings

CORRESPONDENCE makes sure each segment stays timed.
a) you edit transcription
b) switch to timer mode
c) time text you're editing
d) time text while transcribing
just enable TAPtimer keyboard and control PERFECT TIMING right in textarea
call it "correspondence"

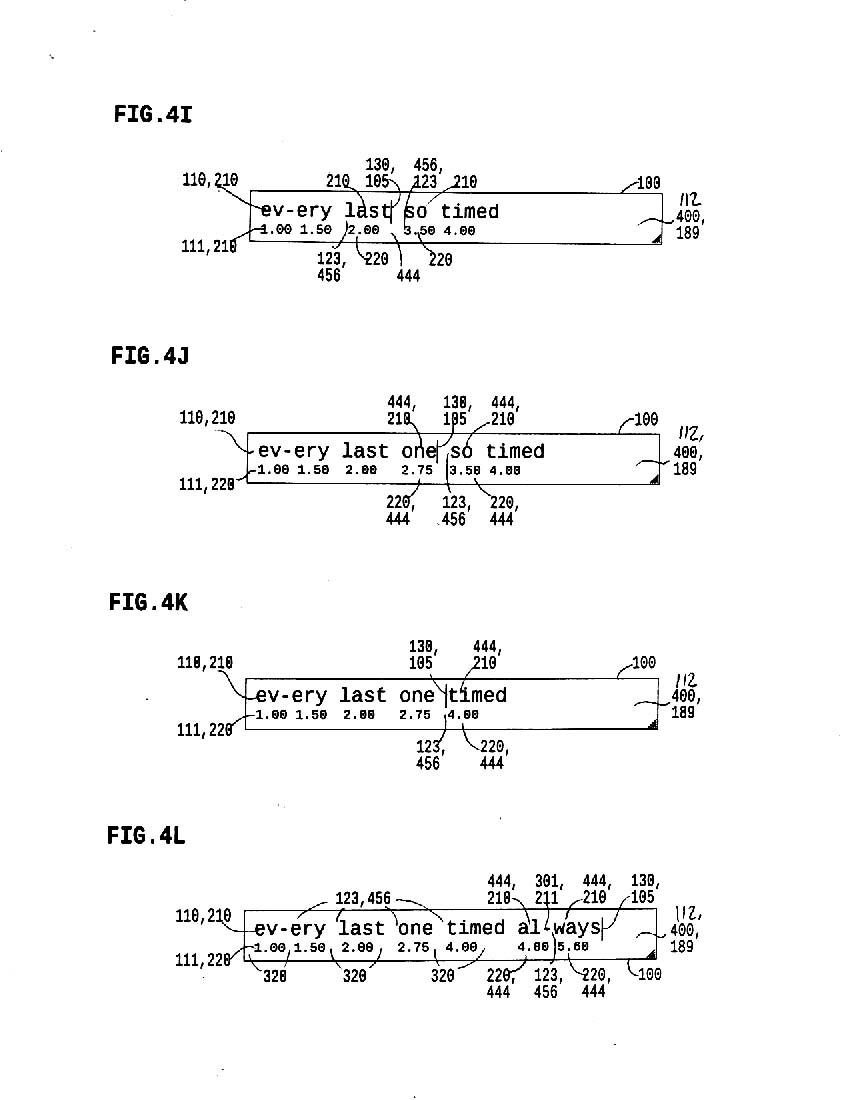
4m shows a new text example with segmentation info hidden
4n shows the text with alignment points marked,
(marked separately for words and syllables within words)
4o shows IPA transliteration aligned by the segment
4p shows segment markers hidden in both text and twext context
FIG 2-4 above show TIME context aligning with text in textarea;
you edit timings directly or switch to timer mode the TAP timings;
CAPcase in plaintext shows synchronous vocal text in any enviroment,
including CLOSED-CAPTIONS, textarea. Above, time context is controlled with text, right in textarea;
alignment is handled within 'n=n' or timing-for-segment limits;
multi-finger TAP process synchronizes plaintext CAPcase element;
text edit, syllabification, pauses, retimings, all handled.
Below, alignment translation context is separately controlled,
where CHUNKs of context align with chunks of text

5a shows example source text, including text, context and alignment guides
5b shows the example aligned by an old method, 2 spaces between all corresponding chunks, now outdated
5c shows the example aligned by the new method, 2 spaces between one of two corresponding chunks, as described below


5d represents chunk pairs controlled where at least two spaces precede one chunk in a pair
5e shows BUMP alignment in unformatted plaintext
align twext in any font, any character set
5f shows proportional-font-formatted textarea text with directly editable aligned context; both texts directly edited, no separate source text required. (note the alignment guides "1:1 3:3 5:6", where third word in context aligns with third word in text "3:3: and fifth word in context aligns with sixth word in text "5:6" .)

note: 5g-5i figure numbering isn't final.. i ran out of numbers
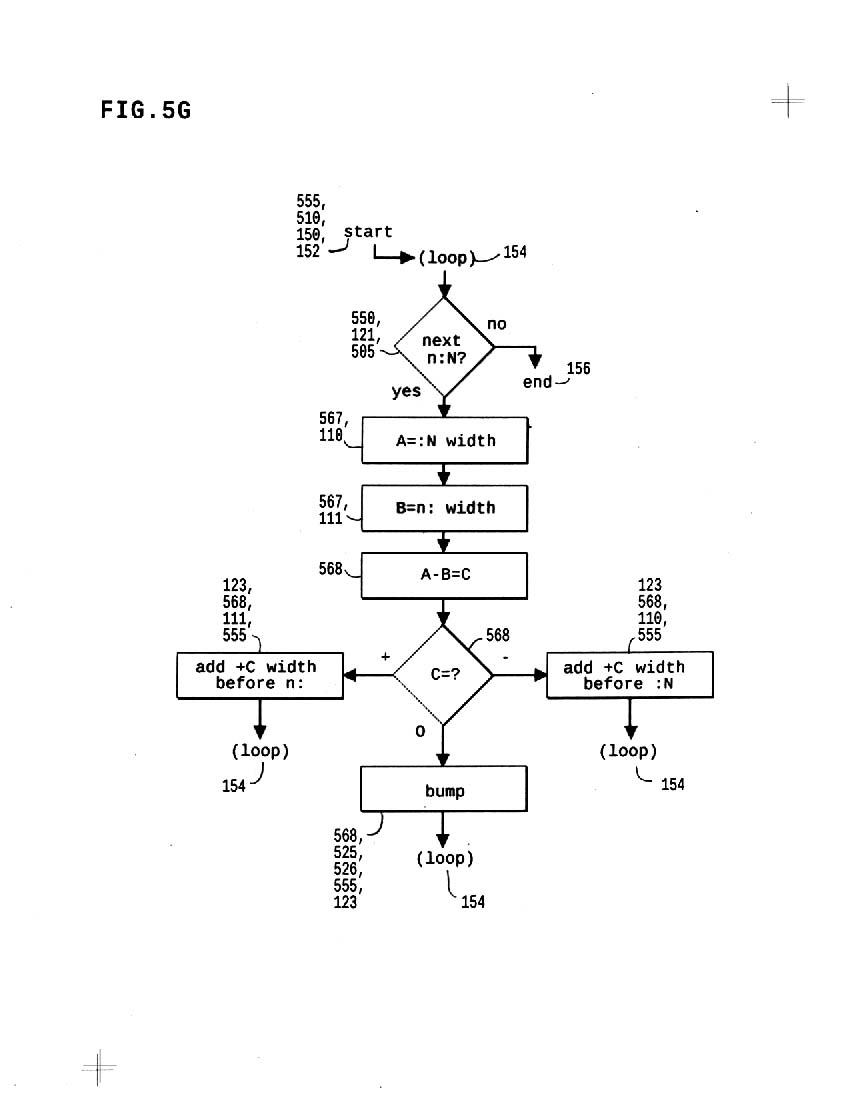
5g shows a simple algorithm to find spaces required to align text/context chunks in single-sized monospace fonts; nothing new here, other than BUMP used to minimize extra spaces, and control INCIDENTAL ALIGNMENT

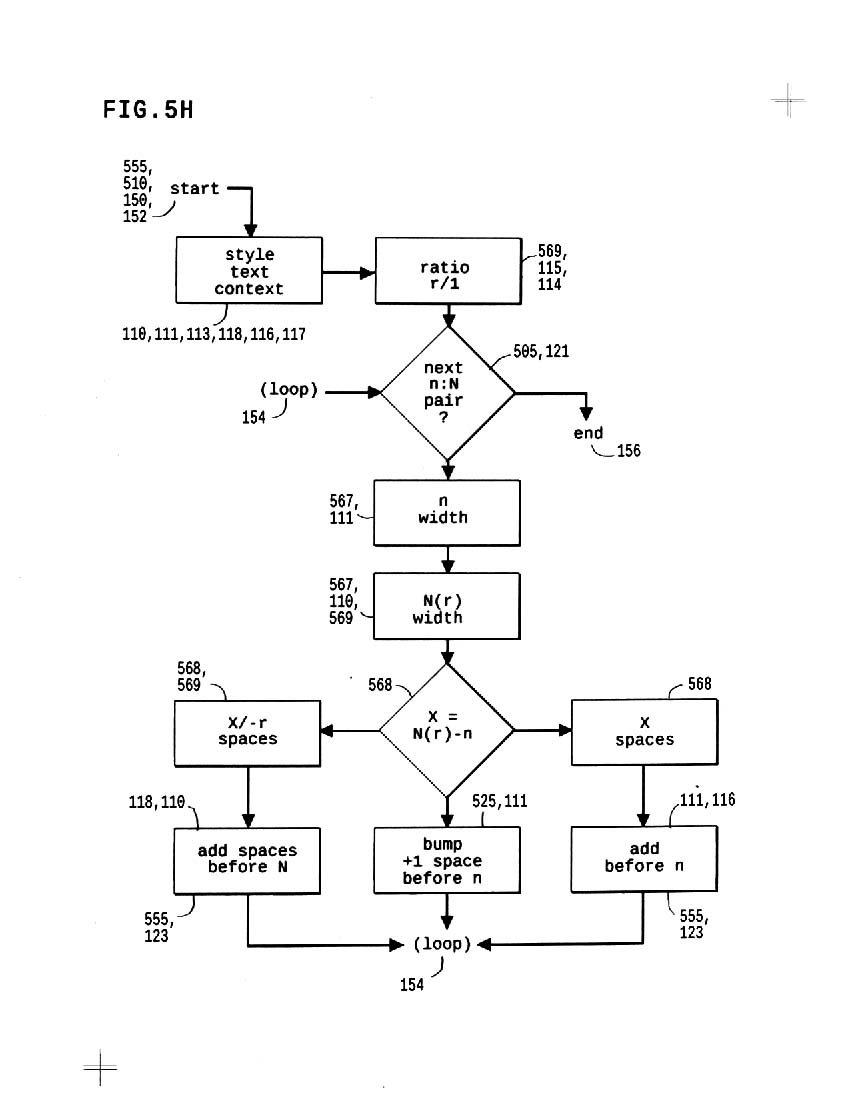
5h shows the known 5g method with ratio applied, so we align variably-sized monospace text/context; in practice, the method delivers uneven results at different font sizes on different systems.


5i applies SPAN within contenteditible in html5; the context chunk is moved one space at a time until aligned with text chunk; if INCIDENTAL ALIGNMENT, we need to know which words are in what CHUNKS, so we BUMP context one space.
Now, in any font, at any sizes, in any language, we can align chunks of context with chunks of text, and within directly editable textarea or "twextarea".
Below you see how to SCOOCH those chunks around, so you can edit exactly what context aligns with which chunk, simply by add/remove space between chunks.

SCOOCH is where twext starts to breath; you easily edit a context chunk and align it with the exact chunk in text you want
pull back
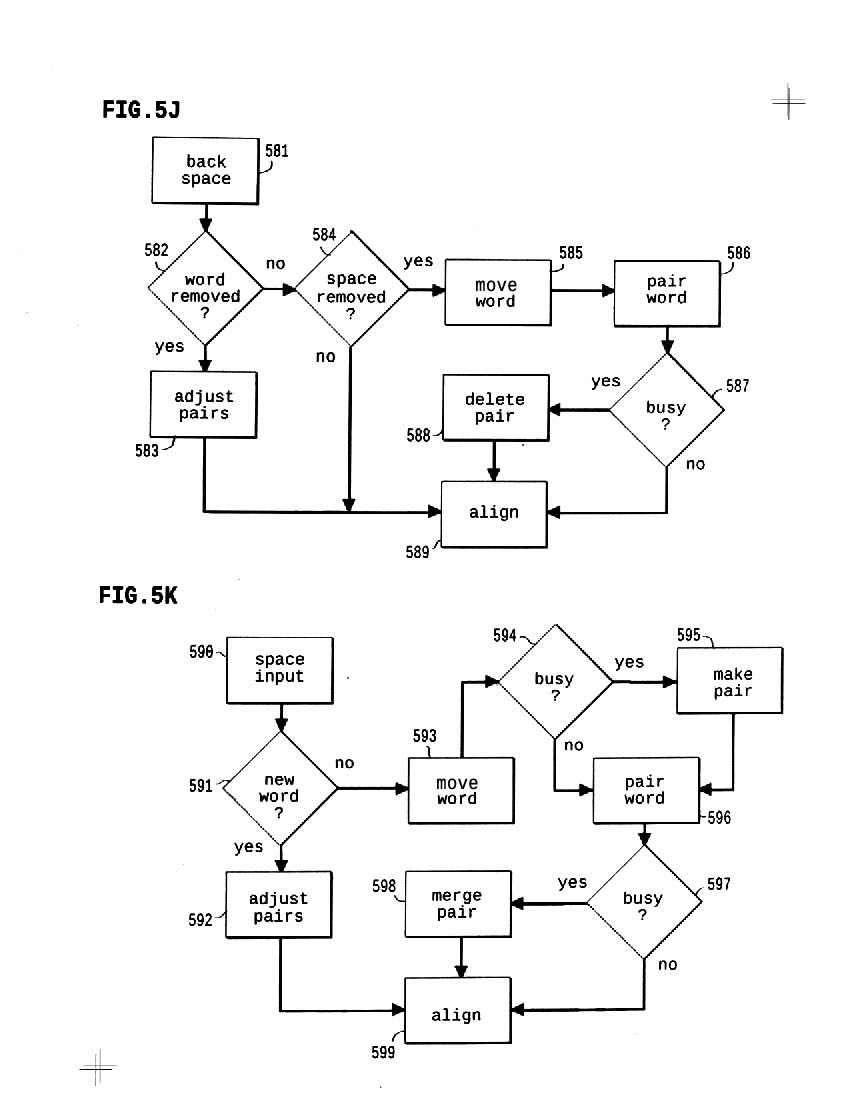
5j shows PULL controls, which interpret backspace or delete input between words while handling exceptions and maintaining the 'n:N' alignment guides
push forth
5K shows PUSH controls, interpreting space input within or between words; PUSH and PULL are tested and work well
Add/remove space between words in either text/context; easily align chunks in context with chunks in text
Detailed examples below


5m one space is added before 2nd context word "context"; PUSH control aligns it with 2nd text word "in".
5n another space added before 2nd context word "context"; PUSH aligns it with 3rd text wrod "text".
5o a space is removed before 2nd context word "context"; PULL control aligns it with 2nd text wrod "in".

5q space added in before 2nd word "in" in big text; scooch chunk one word to right
5r optionally interpret 5q input to align via BUMP (one extra space to delineate context chunks)
5s push context to right (note next chunk is BUSY so next PAIR is deleted from alignment guide)


5u push context, find next chunk BUSY so delete next PAIR
5v edit context (adding extra word); PAIR guides are modified from 2:3 to 3:3
5w edit text (remove second word "in"), PAIR guides are modified from 3:3 to 3:2 (error in drawing)


5y shows blank chunk in context controlled via pair 0:1; first word in context aligns with third word in text (1:3); push/pull controls apply while blank chunks are controlled
5z represents all above controls working with unicode text, with proportional font of any width, and non-space-delineated writing systems are handled
Alignment controls defined above apply to text in segments and/or chunk; two context forms, timings and restatement are seen. In FIG6 series, we combine timings and restatements.

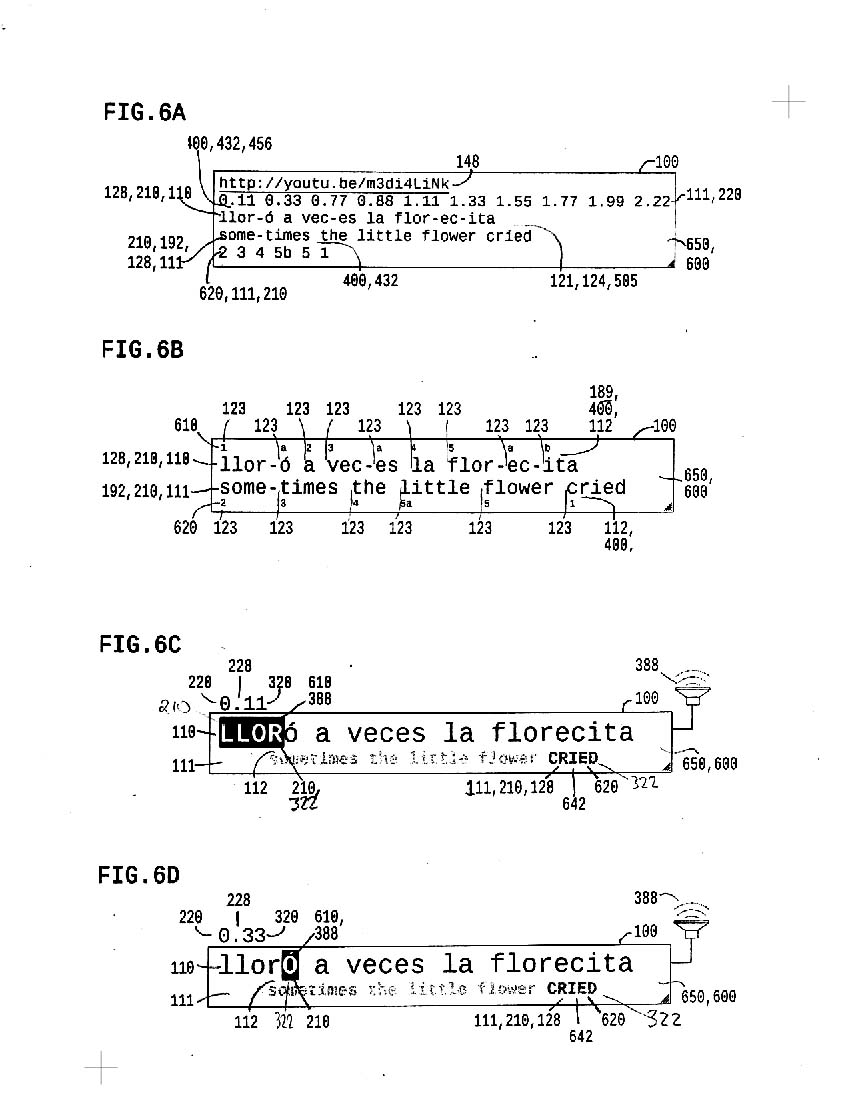
FIG6 SERIES combines timing context with restatement context; for a given recorded vocalization, text segments are perfect timed; perfect timings are applied to restatement context via map. The result is synchronous playback in both text and translation, or linguistic alignment in time.
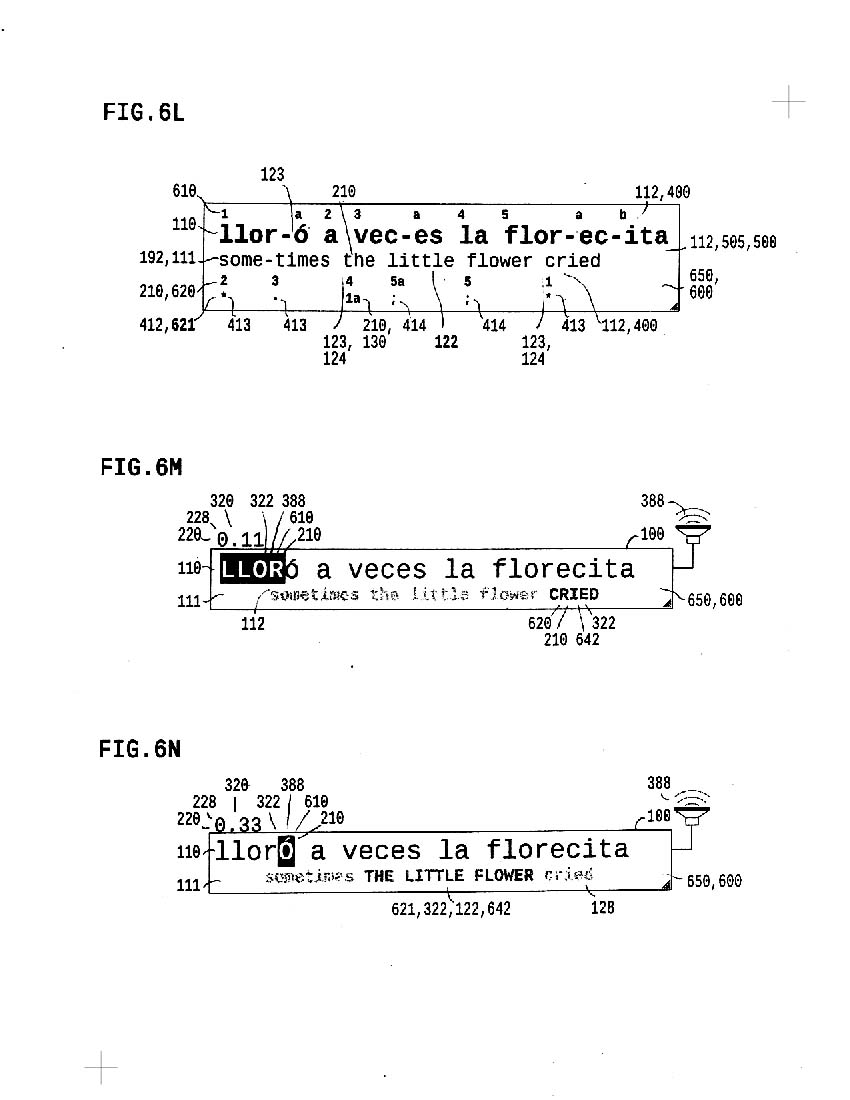
6a shows require data in single-size plaintext
* medialink containing recorded vocalization
* text, segmented into syllables and optional pauses
* timings, one for each text segment
* context, optionally segmented into word parts
* map linking context parts with text segments
6b shows alignment of 6a data in variable size directly editable twext. (Everywhere possible within this system, direct edit control is facilitated, but not intended as exclusive means to input data; there are many way to both map and control the data; what has not been seen is synchronous playback of text and translation, optionally while applying CAPcase)
6c-6k show playback of a single text CHUNK synchronized with translation parts; playback is optionally normal speed or slow; tap playback provides segment by segment playback control
6c shows a first part of a text word in synchronous CAPcase playback while a corresponding word in translation context is highlighted
6d shows a second part of a text word synchronized with two parts of translation context 1) a word part, 2) a complete word


6e shows part of a context word synchronized with a full text word
6f shows part of a context word synchronized with first part of text word
6g shows same part of context word sync'd with second part of text word
6h shows complete context word sync'd with complete text word

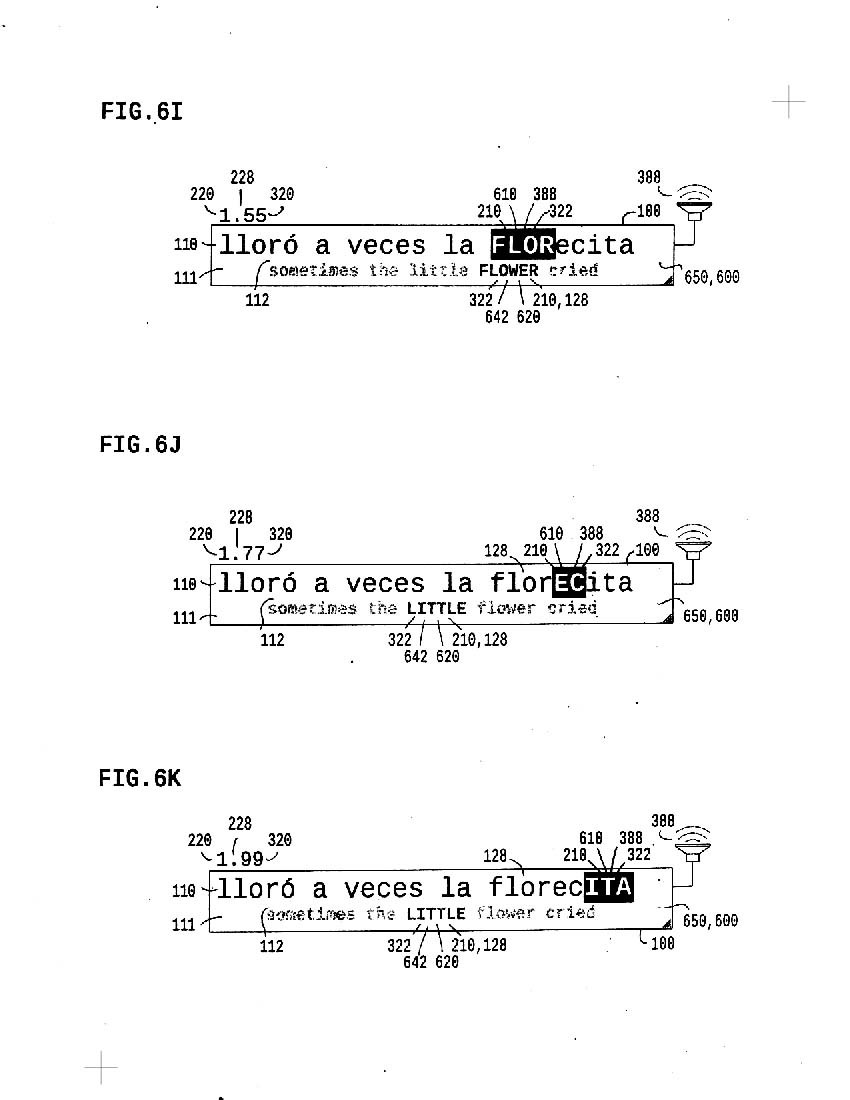
6i-6k show separate text syllables independently sync'd with distinct words in context

6l shows a concurrent second map applied, with multi-word chunk control
6m shows same playback seen in 6c
6n shows three word context chunk sync'd with verbal form in second part of text word
Any number of maps can be added; the result is highly specific linguistic alignment experienced in the dimmension of time.


6o-6p show pointer beneath text hovering over hidden context; system shows translation parts while synchronously playing (CAPcase text *and* audio) vocalization of text part
6q-6r show pointer hovering over text parts; audible vocalization of hovered parts is reproduce, while linguistically aligned translation chunk is temporarily visible
So you experience the sight and sound of synchronous vocal text while only temporarily seeing the translation information.
FIG 1-6 show controls of context alignment in two forms: timings and restatement/translation. Fig 7-9 show other context forms applied and controlled to make text more informative than ever before.

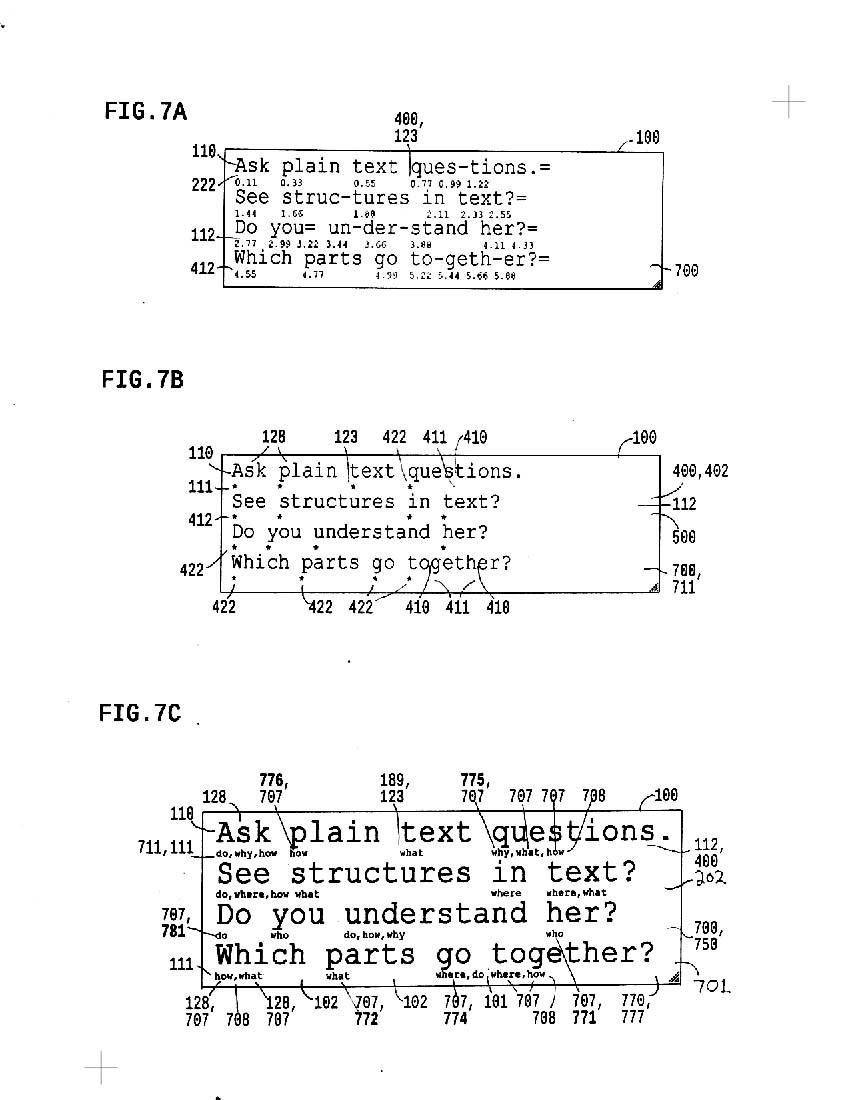
7a shows editable little timings aligned with segmented text
7b shows word alignment points while hiding timing context
tag structure by questions
7c shows context question words or "ASQ" tags aligned with text word
ASQ system simply parses text into segments/chunks labeled by question; structure is defined more by meaning, in comparsion to formal grammatically structures; grammar tags are easily aligned but now shown in this example. Forms of aligned context are easily switched as shown in FIG.9 series


7d shows 7c text with tags hidden and ASQ links listed above
7e shows question word "WHO" input (via mic or click); text words tagged with "who" tag appear in CAPcase, and are also optionally reproduced in audible vocalization
7f"WHAT" is input; words tagged with "what" are distinguished and played in audio
7g "DO" is input; words tagged with "do" are distinguished and played in audio

or how tag text meaningfully?
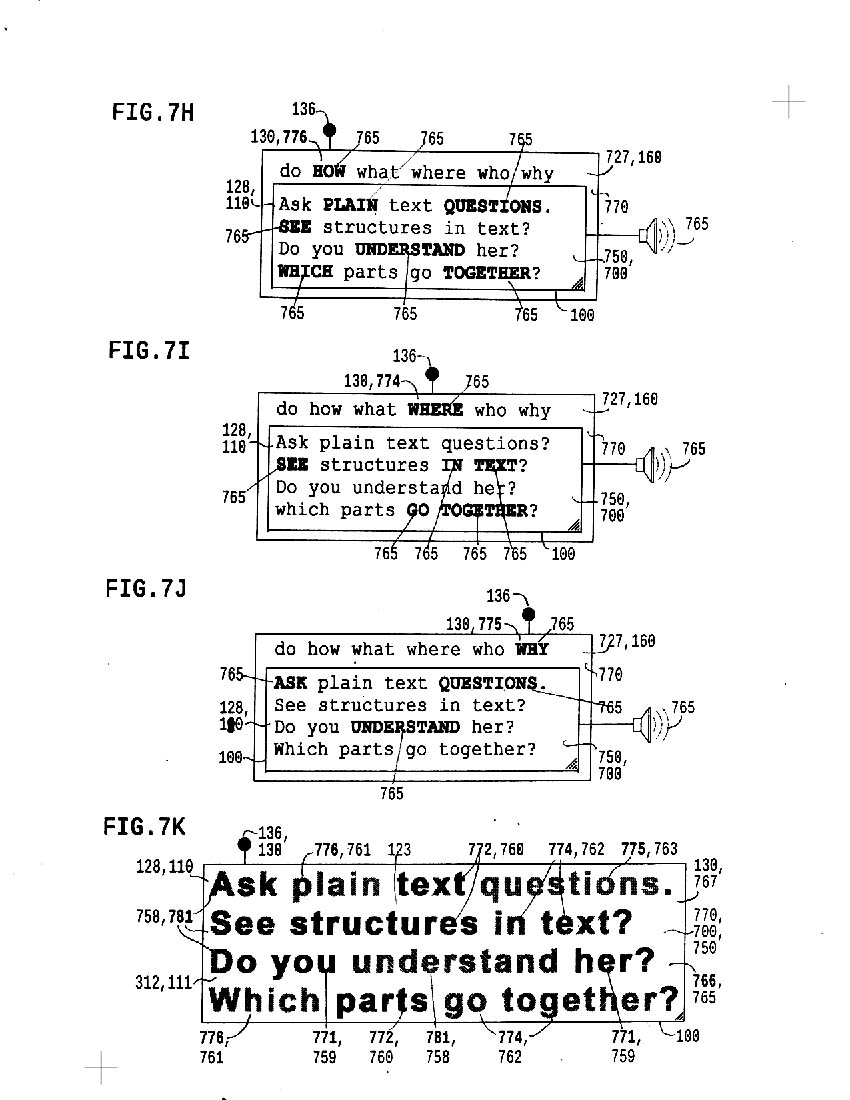
7h "HOW" is input; words tagged with "how" are stressed and played in audio
7i "WHERE" is input; words tagged "where" stressed, played audibly
7j "WHY" is input; words tagged "why" stressed, made audible
7k represents color coding of question tagged text.


7l shows tags aligned simultaneously by the chunk and segment; two arrangments of source text record the directly editable output in the middle; above, a simplified notation is used; below, the explicitly declared chunk pair system is adapted to handle segments within words.
7l shows source text which informs the vocal text experience illustrated in 7m-7p below.


7m-7p show "foreign" language example of ASQ system in use, and also shows the result of tags aligned with all words, chunks and segments in words, as shown controlled in 7l.
7m shows "QUI" input via voice/hover/click; a full word and a segment within another word are made audible and more visible
7n shows "FAIRE" input; a full word is made audible and more visible in text
7o shows "OU" input; a chunk of three words is made audible and more visible in text
7p shows "QUAND" input; both a chunk of four words and a segment within a fifth word is made audible and more visible in text.
The idea with Vocal Text is to get text perfectedly synchronized with a vocalization, then apply the synchronous performance in environments ranging from simple playback to tap controlled playback to playback synchronized with translation to playback parsed by tags such as questions; in all cases, writing system permitting, CAPcase is used to change the form of text parts being heard.
Vocal Text is text you hear. As described below, we control multiple vocalizations of constant text, (so you hear many ways/voices to say the same thing), and we control multiple depictions of any (preferably short) text string.

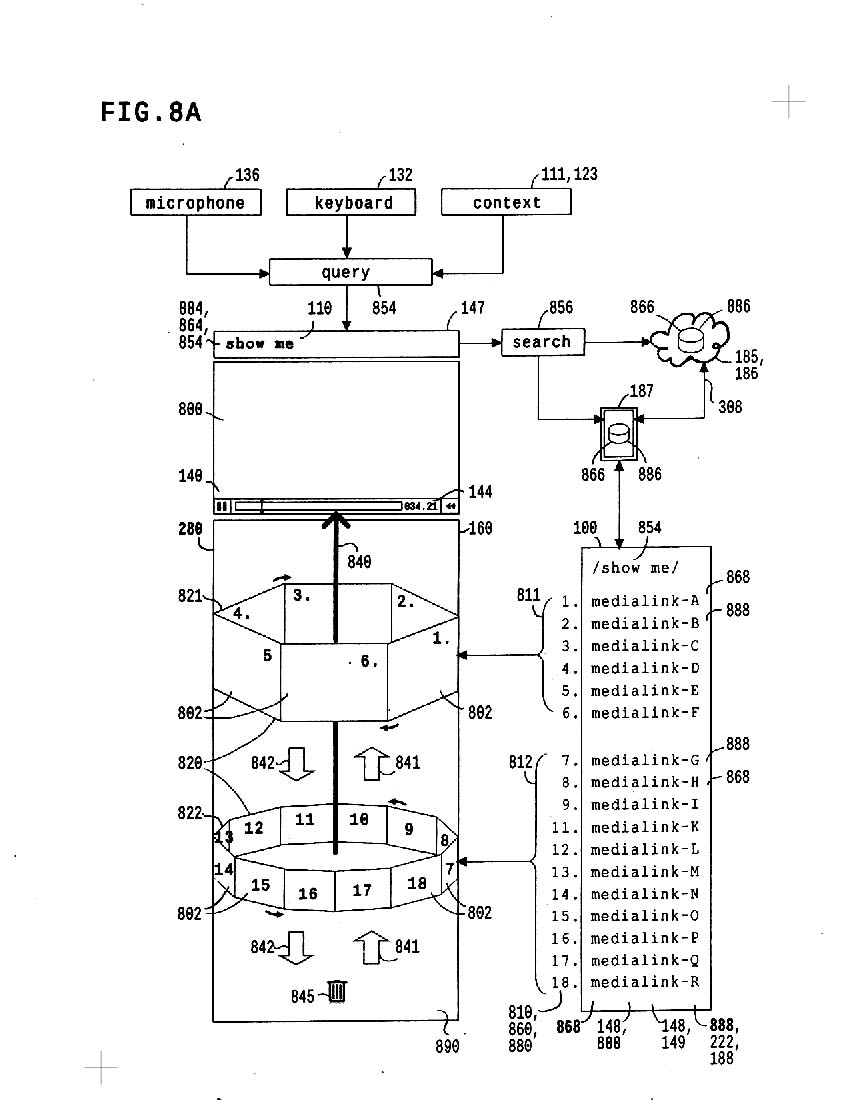
8a represents TIERED CAROUSELS used to ORDER LISTS sort images relevant to a specific text string; lower left, a list of links to pictures (including motion pictures) are controlled; to the right, thumbnails of the pictures are presented in tiered carousels; thumbnails are moved up or down, toward or away from association with the text string; pictures may be viewed in more detail in media player above carousels; text string search query is entered to fetch associated pictures, either from local or internet search.
So a picture dictionary isn't stuck with one picture per word or phrase; phrases are easily associated with multiple pictures.

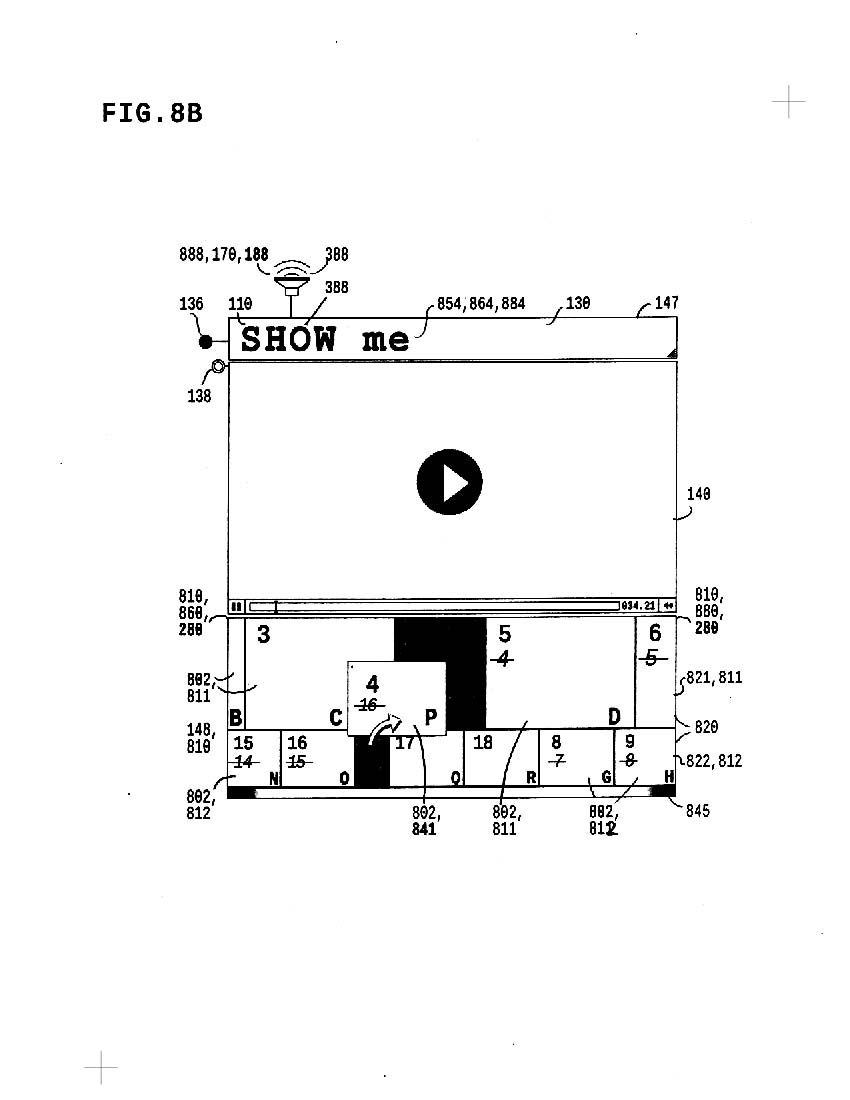
8b shows tiered carousels GUI used in sorting action; order of media links seen in list is changed as picture #16 is moved up to #4 position.
Vocal Text is optionally performed while preferred depictions are sorted up.
Tiered Carousels can also be applied to sort variable vocalizations of constant text strings, where each separate vocalization is represented by a separate picture.


8c represents one vocalization of the example text string "Can you hear me", which is represented in synchronous Vocal Text performance; picture sorter is minimized below.
8d shows picture sorter actived: tiered carousels contain thumbnails of multiple vocalizations of the constant text string; the pointer is seen hovering over list item #28
8e thumbnail previously ordered as #28 from 8d has been dragged onto the Vocal Text playback area, and is now numbered #1 and playbed in maximized media player; a separate vocalization of the same text string is experienced in synchronous Vocal Text.
The internet has vast troves of recorded vocalization in audio and video; vocal text synchronized vocalization precisely with text; thus, vocal text of a specific string can be searched, and various vocalizations of the constant text string can be listed, then sorted in tiered carousels. Sorting decisions are optionally returned to the image search engine, so better depictions are more easily seen.
If you're learning new language or enjoying language you already know and love, you can experience an assortment of vocalized expressions of those words, all performed in synchronous vocal text.


8f widens to present more text surrounding the example string "can you hear me"; the example selected in 8e is fetched from one video performance of the song "Space Oddity"
8g shows the 8f text aligned with context; as shown in FIG 9 series, withing same textarea or "twextarea", multiple context forms are controlled in independent alignment with any text; in the 8g example, depiction context is written
8h depection context from 8g is applied, optionally in conjuntion with text, in IMAGE SEARCH; thumbnails of images found are loaded into tiered carousels and sorted.

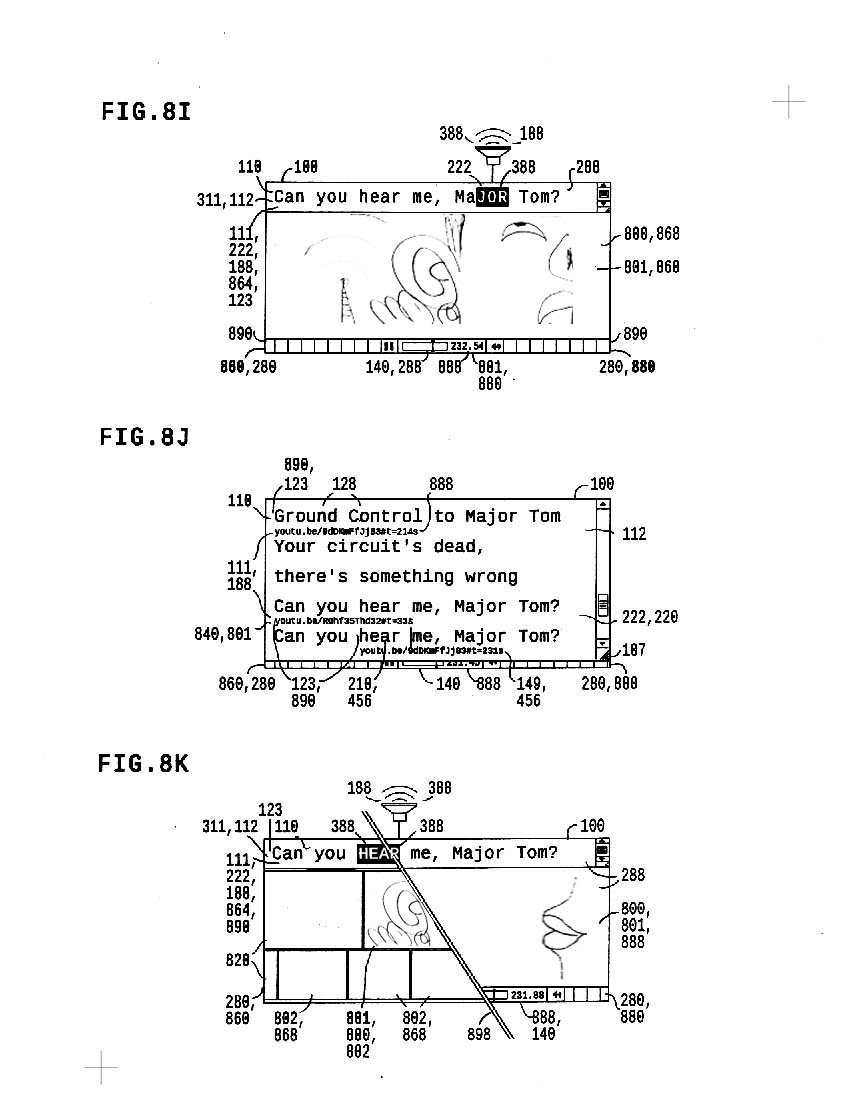
8i shows a select depiction of text string "Can you hear me, Major Tom?" while VocalText is performed
8j shows vocalization context in the form of specific media controlled in alignment with parts in text; multiple vocalizations are assembled to perform a single remix vocalization of the text
8k shows a switch between picture sorter *depictions* of a text string, and large view *vocalization* of the same string; multiple depictions and vocalizations of the string are easily accessed.

FIG-9 SERIES represents TOGGLE CONTEXTS, meaning toggle through multiple contexts, in distinct FORMS then VERSIONS or variations; each context is controlled in INDEPENDENT ALIGNMENT with constant text.
9a shows IPA context, with corresponding segmentation, aligned by the word
9b shows VOCALIZATION context to remix a new vocal performance from existing sources, aligned by the chunk
9c shows perfect TIMING context used to play synchronous VocalText, aligned by the segment
9d shows QUESTION context, defining referential structure in the text, aligned by the word
9e represents TOGGLE access to various context FORMS, each in independent alignment with the text

perfect translation/restatement? it doesn't exist.

9f shows one VERSION of same-language RESTATEMENTS aligned by the chunk
9g shows another separate VERSION of same-language restatement, INDEPENDENTLY ALIGNED with distinct chunks of text
9h shows three VERSIONS of restatement context, each independently aligned with distinct chunks in the text
9i represents TOGGLE fast access to variable VERSIONS controlled within the form of same-language restatement context

perfect translation? doesn't exist.

9j shows one VERSIONS of Spanish translation context aligned by the chunk
9k shows eight versions of Spanish translation context, each independently aligned by the chunk
9l represents SORT control applied to order PREFERRED VERSIONS of Spanish translation context; unwanted versions are placed beneath the empty line
9m represents TOGGLE fast access to multiple versions of Spanish translation context
9n represents SORT control applied where most recent version is moved to most preferred version


9o shows DEPICTION context tags aligned by the chunk
9p shows various VERSIONS of depiction context, each independently aligned by the chunk; note that depiction context is recorded in any written language
9q shows tiered carousel picture sorter loaded with thumbnail depictions suggesting the text string "Can you hear me, Major Tom?"; listed along the bottom row are usernames which link to personalized assortments of depictions of said text string.
9r represents an average of most preferred depictions of said text string.


9s-9v shows a mobile device with camera applied to detect viewers head position; variable head positions detected are applied to TOGGLE both DEPICTION and TRANSLATION context simultanously
9s shows device seen from above; a 1st depiction is seen in the media player; Chinese language translation context is independently aligned by the word
9t shows device seen from left; 2nd depiction in media player; Thai language translation context is seen independently aligned by the chunk
9u shows device seen from the right; 3rd depiction in media player; Russian language translation context, independently aligned by the chunk
9v device seen from below; 4th depiction in media player; Italian language translation context, independently aligned by the chunk.
So you can see all the translation and depiction context you want, with minimal effort; this example assumes you're learning English, Mandarin, Thai, Russian and Italian; concurrently you experience sorted and preferred depictions of the string.

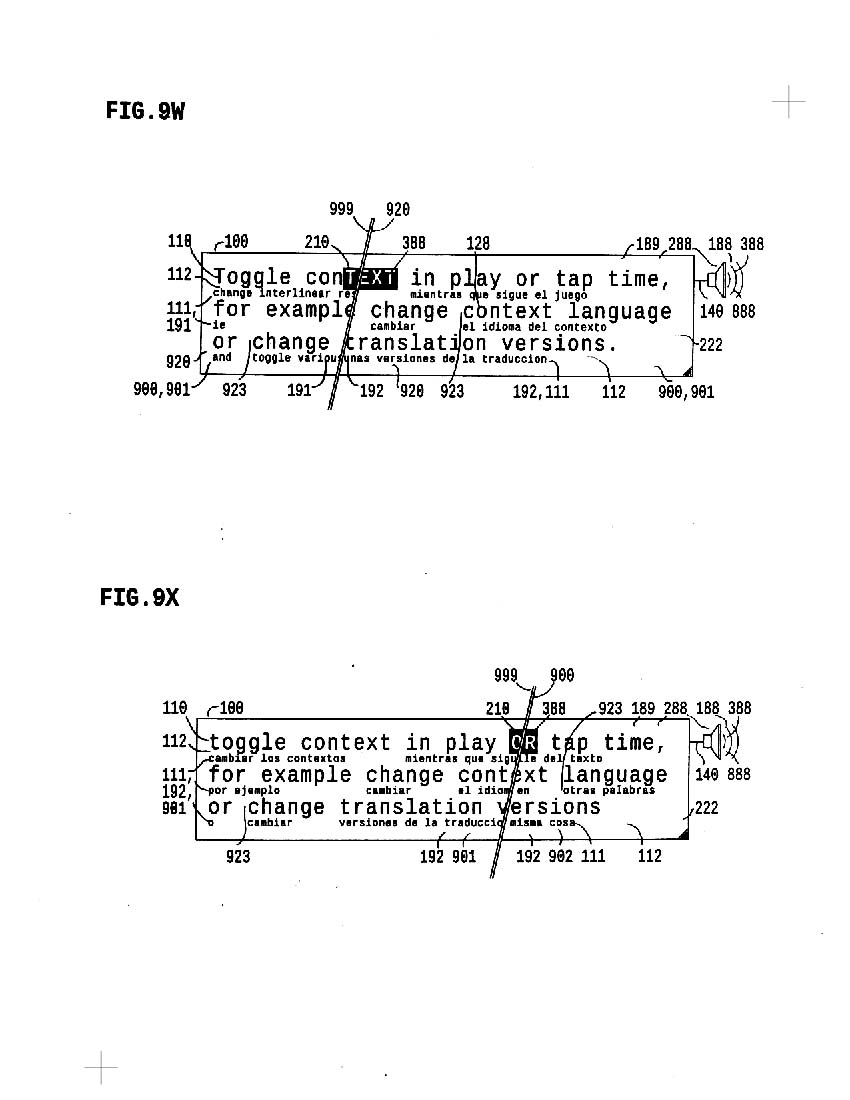
9w-9x affirm that all TOGGLE controls, (applied to vary aligned context forms and versions), can be made while PLAYBACK of perfectly timed synchronous VocalText occurs.
9w shows toggle applied to switch context from Same-Language Restatment to Spanish translation
9x shows toggle applied to switch context from one VERSION of Spanish translation to another version of same
It's understood that each form and version of aligned context is controlled in independent alignment with segments and chunks in text.


FIG.10 series was supposed to define methods to WRAP aligned context, and control contexts in an experiment plaintext data format, but I ran out of time.
10a shows the problem of too much content in aligned context causing unnatural space to appear in text
10b shows context contents truncated
10c shows size of aligned context controlled to fit complete contents


11a represents aligned context printed on computer display, where when viewed from a low angle is invisble
11b shows the context as slightly visible when viewed head-on
11c show the context easily seen when viewed from above
This is a continuation of claims made years ago; aligned context can be the same height relative to text if typeface is narrow.


11d shows light background with white context aligned by chunk
11e shows dark background with black context aligned by chunk
Again, Chunk Aligned contexts can be made detectable but non-intrusive.




Facial detection and image stabilization tools are used to fit each face within a framework; the faces are paired and then combined. CAPcase shown represents VocalText performance in real time; speech recognition and SYNC is applied; error correction of sync'd text handled by TAP controls.


12b represent video capture from two computers; it's understood that face positions vary due to body movements and computer position; synchronous vocal text is seen in performance below.
12c represents a simple framework upon which detected face parts, eyes and mouth, are fit after image stabilization is performed.
12d shows one face fit into the framework
12e shows the other face fit into the framework


12g shows faces combined across horizontal axis; first face mouth below second face eyes above; axis optionally continues clockwise motion
12h shows faces combined side by side; axis rotation optionally continues
12i shows faces combined first face eyes above second face mouth below; axis rotation continues
12f-12i axis rotation can be tested fast to create illusion of a single face, or stopped entirely at a desired position


12j-12m shows same face combination controls described and shown in 12f-12i with vocaltext performance and aligned contexts superimposed; superimposed vocal text positions are optionally controlled.


12o-12p shows faces combined enlarged eyes and mouth like some big baby
12q shows picture sorter applied to sort close-up of lips pronouncing text string "vedi quello che dico"
NOTE: this face combining thing is not at all well developed; processing power available by year 2020 will be *16x* more than today's typical smartphone and I was trying to throw all methods I possibly could into this application filed 15 March 2013, before the USPTO adopted internation standard First to File rules; so kindly overlook less developed elements and focus on the key values: 1. perfectly timed plain-text, 2.) aligned contexts in directly editable textarea and 3.) ample depictions of all text strings, sorted by crowd.
